This post originally appeared on the nteract blog.

Blueprint for nteract
nteract builds upon the very successful foundations of Jupyter. I think of Jupyter as a brilliantly rich REPL toolkit. A typical REPL (Read-Eval-Print-Loop) is an interpreter that takes input from the user and prints results (on stdout and stderr).
Here’s the standard Python interpreter; a REPL many of us know and love.
Standard Python interpreter
The standard terminal’s spartan user interface, while useful, leaves something to be desired. IPython was created in 2001 to refine the interpreter, primarily by extending display hooks in Python. Iterative improvement on the interpreter was a big boon for interactive computing experiences, especially in the sciences.
IPython terminal
As the team behind IPython evolved, so did their ambitions to create richer consoles and notebooks. Core to this was crafting the
building blocks of the protocol that were established on top of
ZeroMQ, leading to the creation of the IPython notebook. It decoupled the REPL from a closed loop in one system to multiple components communicating together.
IP[y]thon Notebook
As IPython came to embrace more than just Python (
R,
Julia,
Node.js,
Scala, …), the IPython leads created a home for the language agnostic parts: Jupyter.
Jupyter Notebook Classic Edition
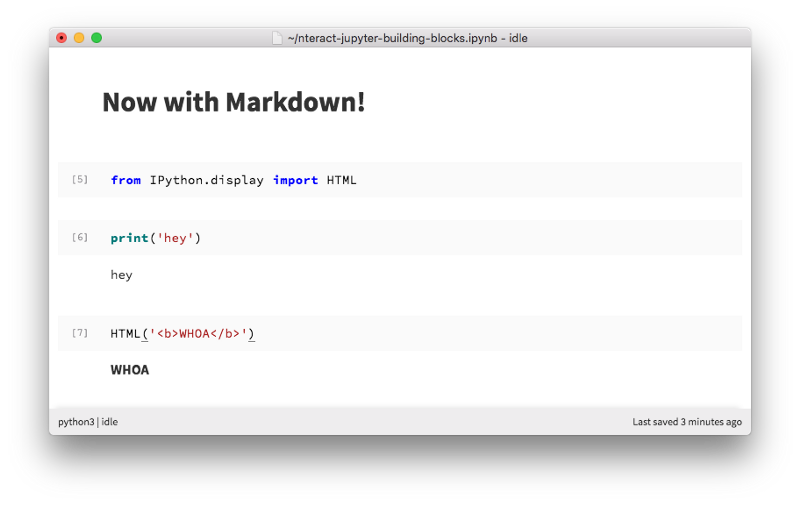
Jupyter isn’t just a notebook or a console.
It’s an establishment of well-defined protocols and formats. It’s a community of people who come together to build interactive computing experiences. We share our knowledge across the sciences, academia, and industry — there’s a lot of overlap in vision, goals, and priorities.
That being said, one project alone may not meet with everyone’s specific needs and workflows. Luckily, with strong support by Jupyter’s solid foundation of protocols to communicate with the interpreters (Jupyter kernels) and document formats (e.g. .ipynb), you too can build your ideal interactive computing environment.
In pursuit of this, members of the Jupyter community created nteract, a Jupyter notebook desktop application as well as an ecosystem of JavaScript packages to support it and more.
What is the platform that Jupyter provides to build rich interactive experiences?
To explore this, I will describe the Jupyter protocol with a lightweight (non-compliant) version of the protocol that hopefully helps explain how this works under the hood.
Also a lightweight Hello WorldWhen a user runs this code, a message is formed:
We send that message and receive replies as JSON:
We’ve received two types of messages so far:
- execution status for the interpreter — busy or idle
- a “stream” of stdout
The status tells us the interpreter is ready for more and the stream data is shown below the editor in the output area of a notebook.
What happens when a longer computation runs?

Sleepy time printing
As multiple outputs come in, they get appended to the display area below the code editor.
How are tables, plots, and other rich media shown?
Yay for DataFrames!
Let’s send that code over to see
The power and simplicity of the protocol emerges when using the execute_result and display_data message types. They both have a data field with multiple media types for the frontend to choose how to represent. Pandas provides text/plain and text/html for tabular data
text/plain
text/html
When the front-end receives the HTML payload, it embeds it directly in the outputs so you get a nice table:
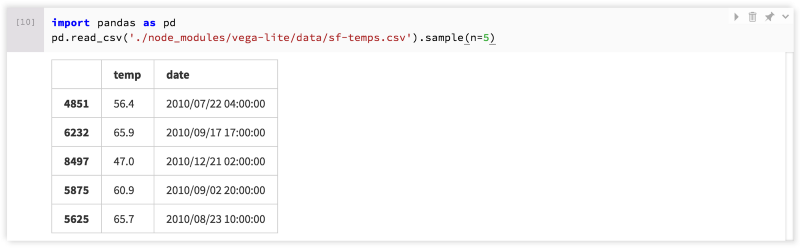
DataFrame to Table
This isn’t limited to HTML and text — we can handle images and any other known transform. The primary currency for display are these bundles of media types to data. In nteract we have a few custom mime types, which are also
coming soon to a Jupyter notebook near you!
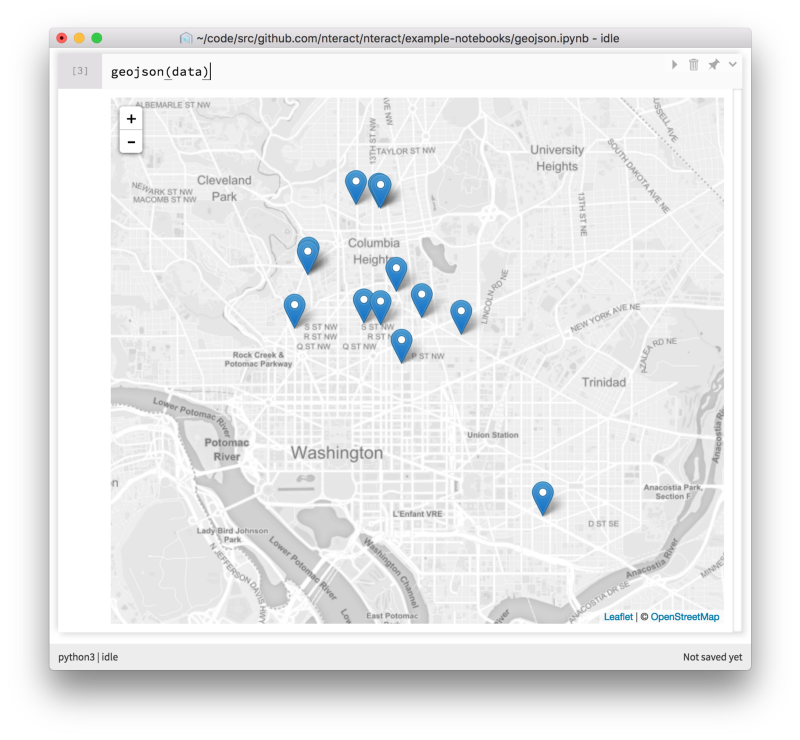
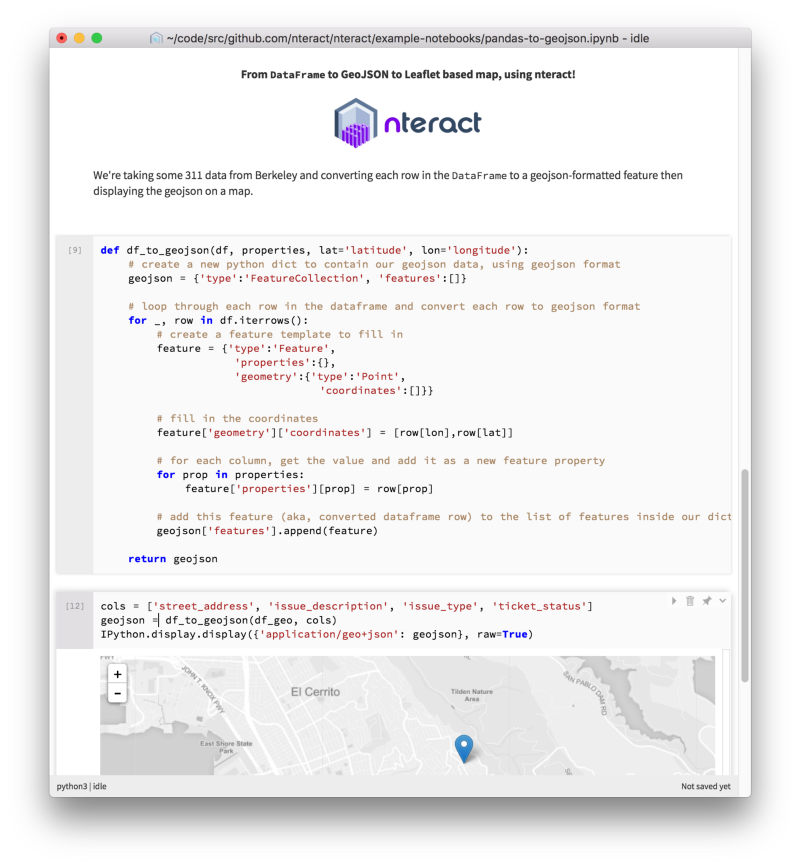
GeoJSON in nteract
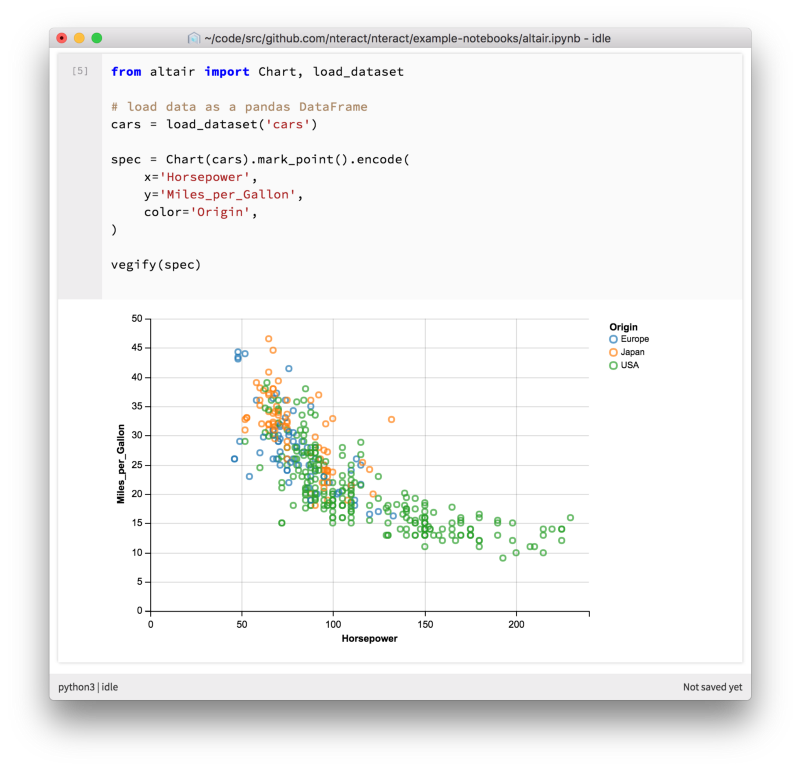
Vega / Vega-lite via Altair (https://github.com/altair-viz/altair)
How do you build a notebook document?
We’ve witnessed how our code gets sent across to the runtime and what we receive on the notebook side. How do we form a notebook? How do we associate messages to the cells they originated from?
We need an ID to identify where an execute_request comes from. Let’s bring in the concept of a message ID and form the cell state over time
We send the execute_request as message 0001
and initialize our state
Each message afterward lists the originating msg_id as parent_id 0001. Responses start flowing in, starting with message 0002
Which we can store as part of the state of our cell
Here comes the plain text output in message 0003
Which we fold into an outputs structure of our cell
Finally, we receive a status to inform us the kernel is no longer busy
Resulting in the final state of the cell
That’s just one cell though —what would an entire notebook structure look like? One way of thinking about a notebook is that it’s a rolling work log of computations. A linear list of cells. Using the same format we’ve constructed above, here’s a lightweight notebook:
As well as the rendered version:
As Jupyter messages are sent back and forth, a notebook is formed. We use message IDs to route outputs to cells. Users run code, get results, and view representations of their data:
This very synchronous imperative description doesn’t give the Jupyter protocol (and ZeroMQ for that matter) enough credence. In reality, it’s a hyper reactor of asynchronous interactive feedback, enabling you to iterate quickly and explore the space of computation and visualization. These messages come in asynchronously, and
there are a lot more messages available within the core protocol.
I encourage you to get involved in both the nteract and Jupyter projects. We have plenty to explore and build together, whether you are interested in:
Feel free to reach out on issues or the nteract slack.